Comparing NK Problem Instances¶
Download this as a Jupyter notebook
This notebook compares 3 NK instances. We will focus on two xLA features: fitness distance correlation (pyxla.fdc()) and variable importance (pyxla.X_imp())
An NK landscape has the following components:
The number of bits \(n\), such that solutions in the search space are of the form \(\{x_0, x_1, ..., x_{n-1}\}\),
The number of neighbours per bit \(k\),
A set of \(k\) neighbours \(\mathcal{N}(x_i)\) for every bit in \(\{x_0, x_1, ..., x_{n-1}\}\); the contribution of each \(x_i\) to the fitness of a given configuration is said to depend on both \(x_i\) and its \(k\) neighbours,
A subfunction \(g_i\) defining a real value for each of combination of values of \(x_i\) and \(\mathcal{N}(x_i)\), where \(g_i\) is typically a lookup table.
Each of 3 NK problem instances have \(n = 14\) with varying difficulty of optimisation defined by their \(k\) values and are sampled by full enumeration. The parameter \(k\) influences the ruggedness of the landscape. The easiest of the three had \(k = 1\), the next one had \(k=2\), and the hardest of the three had \(k=4\). Increasing the value of \(k\) makes the landscape more rugged and thus harder to solve.
We load the NK instances:
from pyxla.util import load_sample
nk_n14_k1 = load_sample('nk_n14_k1')
nk_n14_k2 = load_sample('nk_n14_k2')
nk_n14_k4 = load_sample('nk_n14_k4')
Fitness distance correlation (FDC)¶
Beware: the NK problem instances are fully enumerated so they each have 16386 solutions. The resulting D file is about 3GB, and is not provided in the sample. Thus execting pyxla.fdc() will attempt to compute the D file potentially crashing the system or taking too long!
from pyxla import fdc
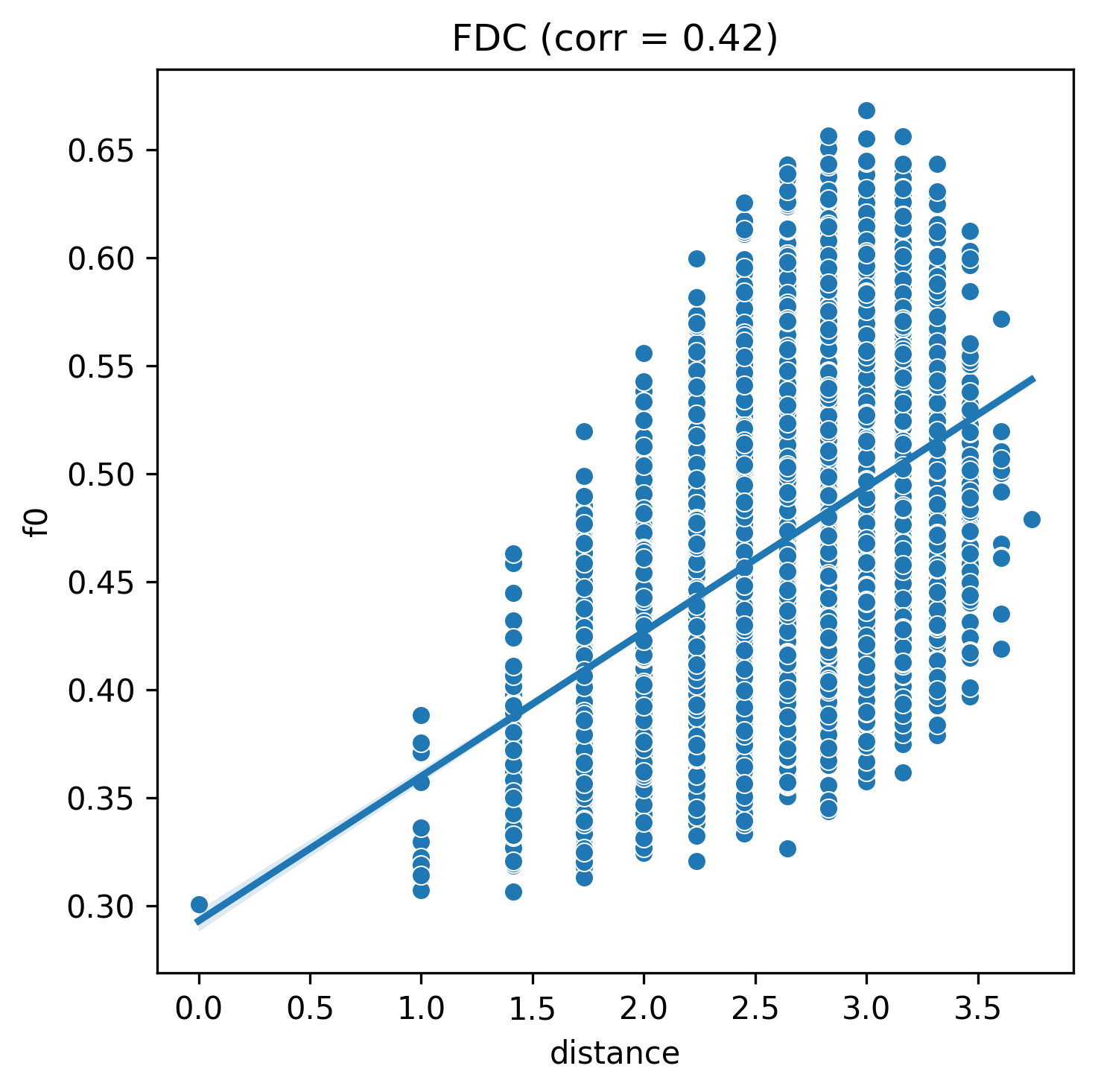
corr, plot = fdc(nk_n14_k1)
corr
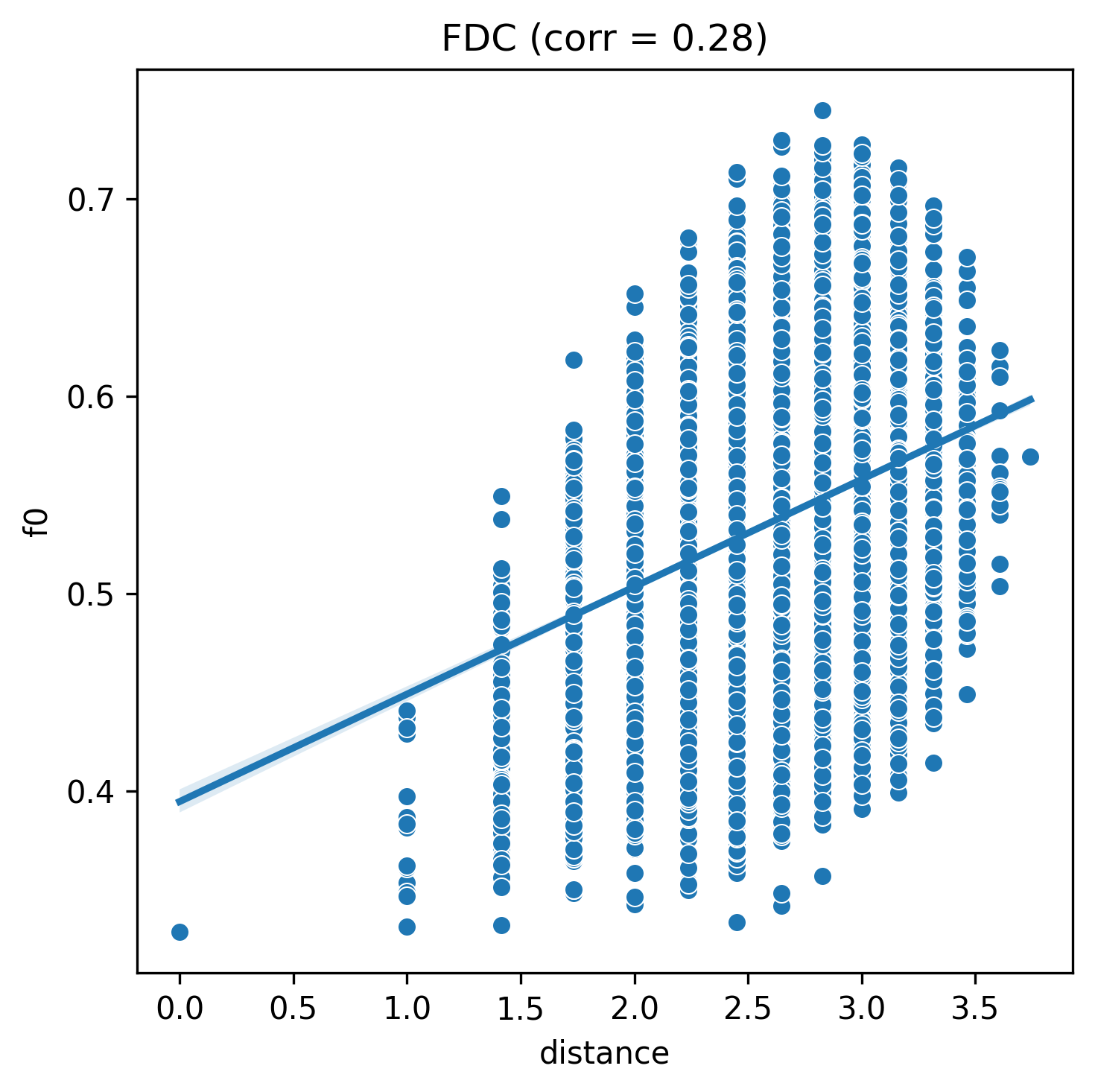
corr, plot = fdc(nk_n14_k2)
corr
corr, plot = fdc(nk_n14_k4)
corr
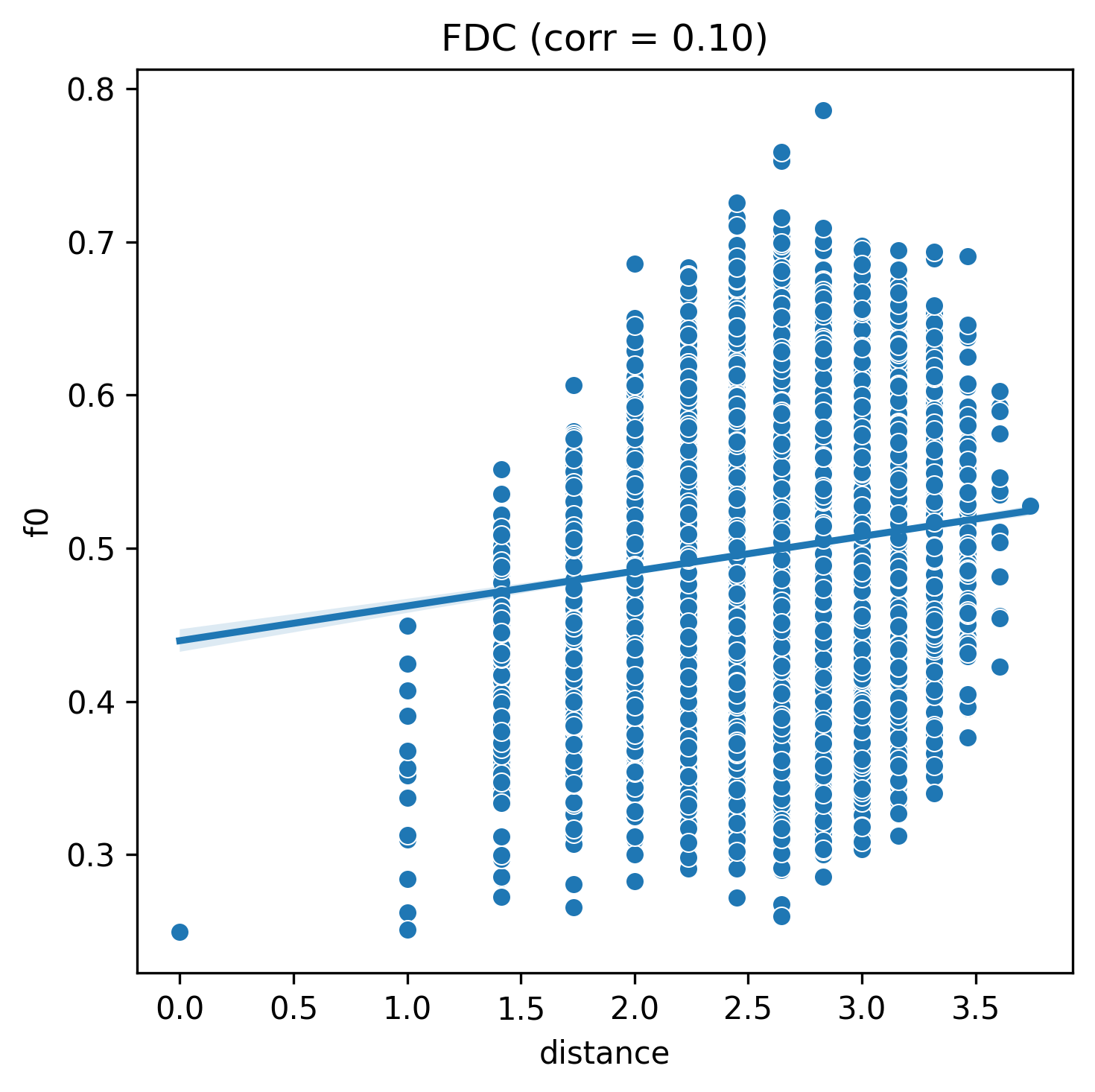
pyxla.fdc() shows that the three NK fitness landscape instances are increasing in difficulty with increasing values of \(k\). For values of \(k\), 1, 2, 4, the fitness distance correlation reduces respectively as expected.
This confirms that increasing values of \(k\) reduce the likelihood that a search will reach the global optimum, as the relationship between a solution’s fitness and its distance to the global solution weakens with increasing values of \(k\).
Variable Importance (X_imp)¶
Permutation feature importance was evaluated using a Lasso regression model.
from pyxla import X_imp
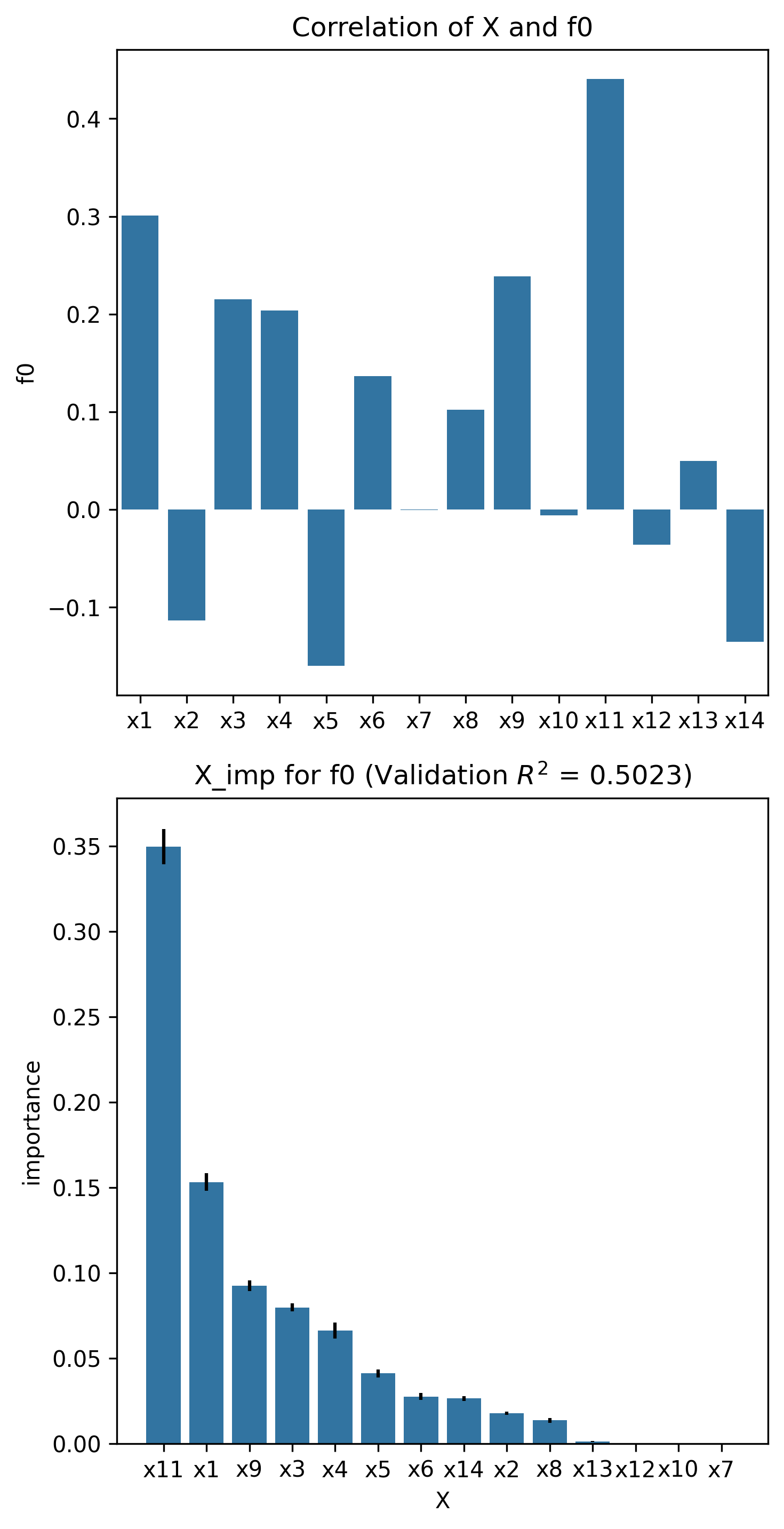
corr_matrix, x_imp_ranks, plot = X_imp(nk_n14_k1, estimator="lasso")
corr_matrix, x_imp_ranks, plot = X_imp(nk_n14_k2, estimator="lasso")
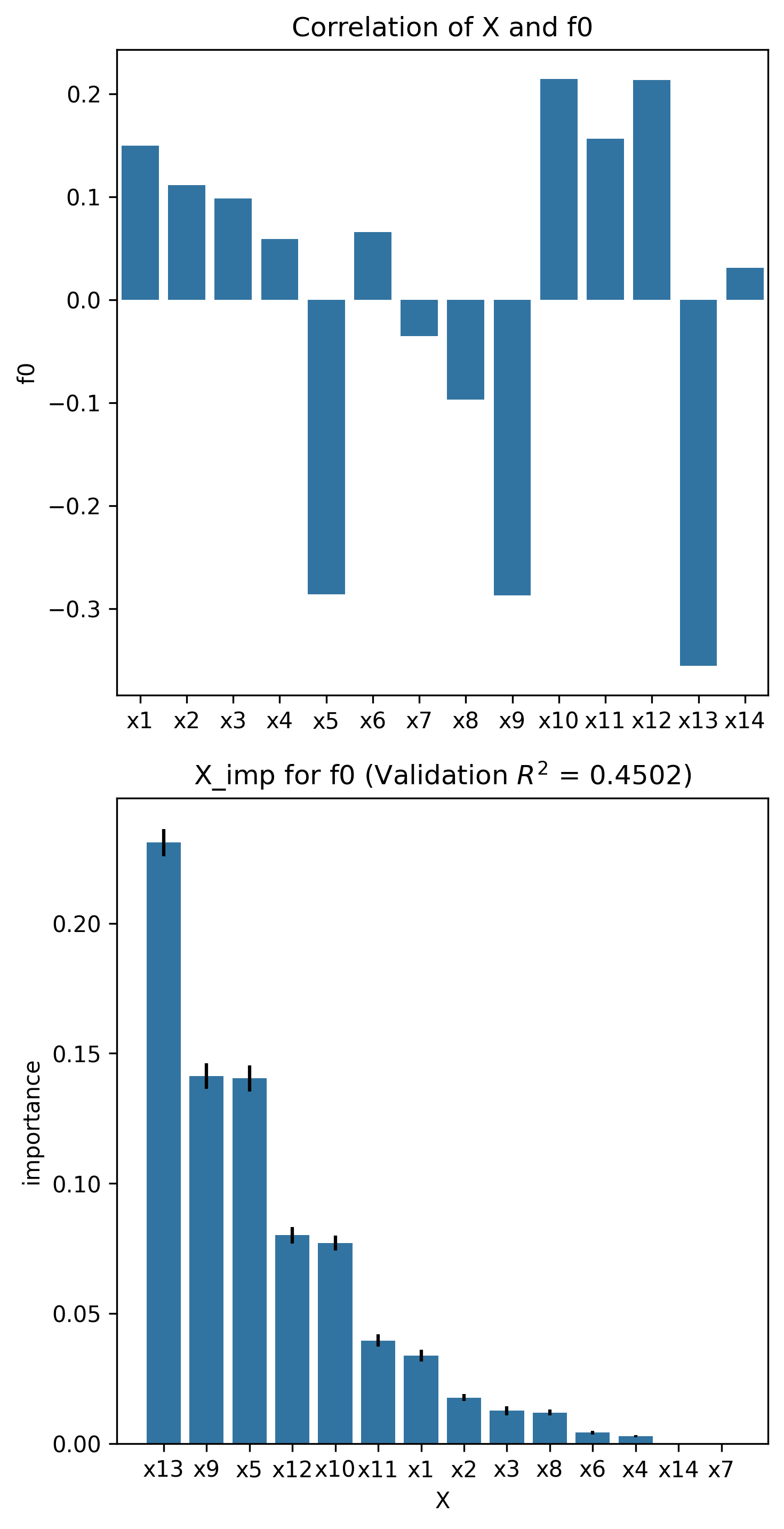
corr_matrix, x_imp_ranks, plot = X_imp(nk_n14_k4, estimator="lasso")
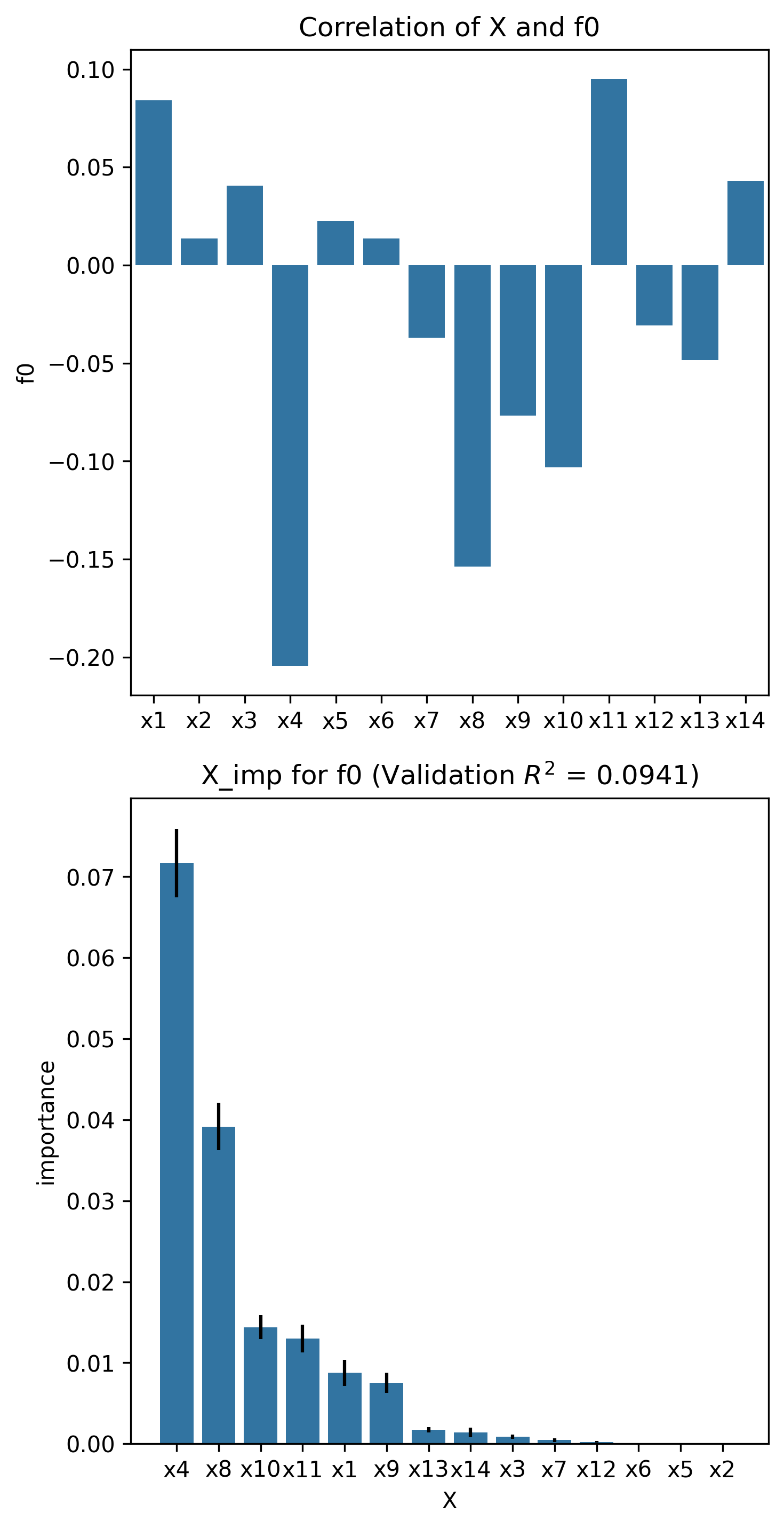
It should be noted that there is agreement between the correlation coefficients and the permutation feature importance scores. Additionally, in general, the higher the value of \(k\), the lower the correlation with the objective, and the lower the permutation feature importance score. This is consistent with the property of NK problems increasing in complexity with higher values of \(k\). As complexity increases, the individual contribution of each variable reduces as its contribution depends on not only the variable itself but also on other variables, a dependency which worsens with increasing values of \(k\).