Analysing Samples¶
Download this as a Jupyter notebook
This guide covers how to use pyXla to conduct landscape analysis.
The first step is to load a sample:
from pyxla.sampling import HilbertCurveSampler
from pyxla import load_data
sampler = HilbertCurveSampler(
sample_size=100, dim=2, return_neighbourhood=True
)
sample = {
"X": sampler,
"F": lambda x: (x**2).sum(),
"V": lambda x: ((x**2).sum() - 3),
"D": lambda x1, x2: ((x1 - x2)**2).sum(), #must take a pair of arguments and real number
# N file is provided by the sampler since return_neighbourhood=True
}
load_data(sample)
The next step, is to import the explainable landscape analysis (xLA) feature of choice. For instance we import the distr_f (distribution of objective values) below:
from pyxla import distr_f
Lastly, invoke the imported feature.
feat, plot = distr_f(sample)
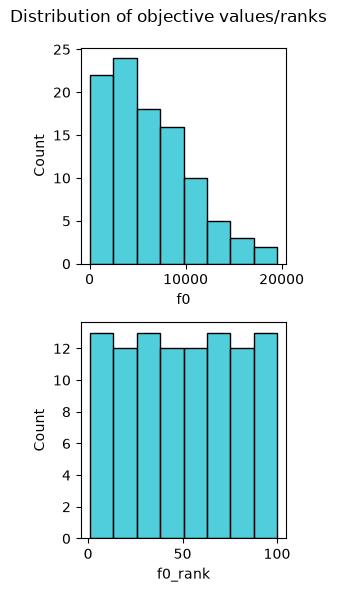
Each xLA feature in pyXla produces as output both visual and numerical outputs. For most features these outputs are returned as a pair.
The numerical output is the first item in the pair:
feat
{'f0_min': 47.74733335103771,
'f0_max': 19518.104772404447,
'f0_mean': 6184.863179875942,
'f0_med': 5125.585521819421,
'f0_q1': 2646.775591121651,
'f0_q3': 8900.576728565282,
'f0_sd': 4425.50039882972,
'f0_skew': 0.7742824681461509,
'f0_kurt': 0.10862431561468888,
'f0_rank_min': 1,
'f0_rank_max': 100,
'f0_rank_mean': 50.5,
'f0_rank_med': 50.5,
'f0_rank_q1': 25.25,
'f0_rank_q3': 75.75,
'f0_rank_sd': 29.011491975882016,
'f0_rank_skew': 0.0,
'f0_rank_kurt': -1.2002400240024003}
The visual output is the second item in the pair:
plot
For a complete reference of all the xLA features implemented in pyXla see the API reference.